Mi Trabajo/Proyecto Fin de Grado [TFG/PFG]
En este artículo describiré en qué ha consistido mi proyecto fin de grado de Ing. Informática, titulado “Investigación y desarrollo de técnicas de análisis de la seguridad web a partir de crawling” y presentado de forma telemática (por consecuencias del COVID-19) el día 30 de junio a las 10:30 con una duración de alrededor de 30 minutos (preguntas del tribunal incluidas).
Investigación y desarrollo de técnicas de análisis de la seguridad web a partir de crawling
Autor: Alberto Fernández de Retana
Director: David Buján
Grado: Ingeniería informática
Nota: 9.5
2019-2020
Índice
- Introducción
- Desarrollo del proyecto
- Ejemplo de la herramienta
- Evaluación de la herramienta in the wild
- Conclusión
- Links
Introducción
La web se ha convertido en una parte esencial de nuestras vidas, millones de personas hacen uso de ella diariamente para multitud de propósitos, desde leer el periódico hasta gestiones del banco, es por ello que no solo los ciberdelincuentes han puesto el punto de mira en esta tecnología, si no que también entidades legales han desarrollado métodos de trackear o sacar provecho de los usuarios mientras navegan por internet.
Cada vez se está poniendo más de relieve para personas, empresas y estados que la seguridad es un pilar muy importante de las nuevas tecnologías, y no algo tan secundario como hasta hace no mucho. Por ello, al igual que se han vuelto más complejos los ataques que se producen en la web, también se han sofisticado mucho las contramedidas para que no se produzcan o, al menos, se mitiguen, reduciendo en gran medida su impacto. En este proyecto, nos vamos a centrar en los ‘‘crawlers’’ y los posteriores análisis que se pueden realizar con ellos, ya que se trata de una técnica muy extendida para multitud de funciones y no solo enfocada en la seguridad, convirtiéndose así en una contramedida de gran valor.
¿Qué es un crawler?
Un crawler, que en castellano se podría traducir como “araña web”, es un programa informático desarrollado en un lenguaje de programación capaz de escanear páginas webs de la WWW de una forma metódica y automatizada. Como podemos observar en la definición, su uso no tiene por qué estar estrictamente enfocado en la seguridad.
Uno de estos posibles usos, ajenos a la seguridad, puede ser el asociado al crawler Heritrix, desarrollado en Java, ya que es usado por Internet Archive para rastrear, recopilar y almacenar páginas web a modo de archivo WWW en el tiempo. Otro posible uso más enfocado en la seguridad podría ser el asociado a Photon, que está desarrollado en Python con un enfoque OSINT (Open Source Intelligence), recogiendo datos de fuentes disponibles de forma pública para ser utilizados en un contexto de inteligencia. Un ejemplo de sus funcionalidades, entre otras, es recopilar los emails o cuentas de RRSS que se encuentren en un dominio concreto.
Introducción a este proyecto
En el presente proyecto haremos uso de un crawler desarrollado por terceros, añadiendo alguna funcionalidad e implementando un analizador de los resultados obtenidos a partir del mismo. El crawler que se va a utilizar es una reimplementación en otra interfaz más a bajo nivel de otro crawler realizado con anterioridad. El anterior crawler llamado TrackingInspector fue desarrollado en el contexto de la tesis doctoral de un compañero del grupo de investigación de DeustoTech, pero que estaba centrado en la privacidad web y en el tracking de usuarios. Este crawler estaba basado en el proyecto PhantomJS y se reimplementó en una interfaz del protocolo de depuración de Chromium para Node.
La solución desarrollada en este proyecto será capaz de analizar páginas web a partir de sus URLs y de parametrizar cómo deseamos llevar a cabo el análisis y cómo realizar el informe de salida del mismo, por ejemplo, por pantalla o exportando un documento HTML más amigable para un usuario humano. Por otra parte, se hará uso también de otros proyectos y desarrollos para complementar la información de nuestro análisis.
Este proyecto se basa en desarrollar un analizador enfocado en el crawler comentado, pero que utiliza técnicas para descubrir actividades sospechosas y que podrían ser fácilmente adaptadas para otros proyectos. Además, este analizador será implementado de una forma modular, permitiendo añadir o quitar funcionalidades de una manera sencilla, sin interferir con el resto de procesos llevados a cabo. Por otra parte, el IsKrawler Analyzer implementará diversas técnicas presentadas en diferentes conferencias de seguridad web convirtiéndolo en una solución más amplia, accesible y útil.
Desarrollo del proyecto
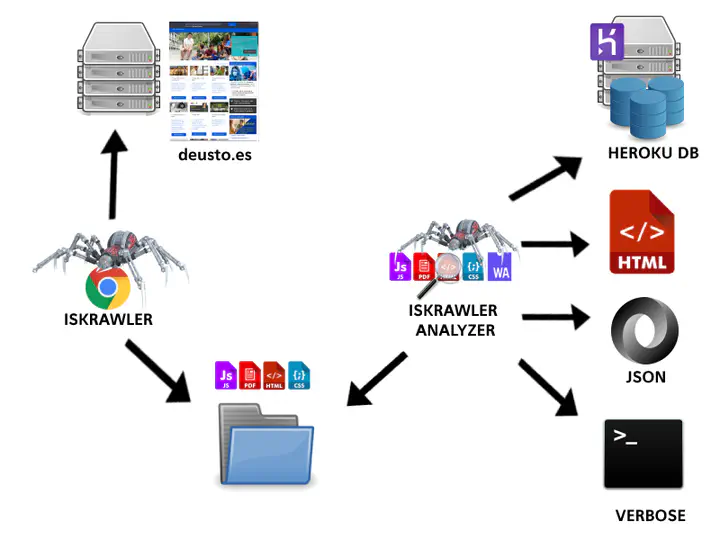
El desarrollo del proyecto ha consistido en dos partes bien diferenciadas:
- La primera, en añadir nuevas funcionalidades en el crawler (IsKrawler).
- La segunda, desarrollar un analizador de los resultados del crawler (IsKrawler Analyzer).
Añadidos al IsKrawler
En este apartado se describen los añadidos realizados al crawler para mejorarlo. El crawler está desarrollado en JavaScript (JS) haciendo uso del proyecto chrome-remote-interface para controlar el navegador mediante el protocolo de depuración. El hacer uso de este proyecto en vez de otros como Selenium, PhantomJS o otros, nos permite recoger toda la información de las operaciones que realiza el navegador a bajo nivel.
El primer gran añadido fue que recogiese los WebAssembly, en caso de que la página en cuestión tuviese alguno. Los WebAssembly son una tecnología nueva en la que básicamente son ejecutables de código que se ejecutan en el cliente y que tienen grandes ventajas de velocidad frente al código JS. En este añadido me gustaría comentar el caso curioso que me ocurría, y es que los Wasm (Web Assembly) eran reconocidos como un recurso del tipo ‘Fetch’ por el navegador, y no he encontrado todavía que otros tipos de ficheros se engloban en esta categoría.
El segundo añadido fue que recogiese toda comunicación mediante WebSockets. Las conexiones mediante Web Socket proporcionan una comunicación full-duplex por TCP. Este añadido nos permite recoger con qué endpoint se conecta y toda la conversación que se haya realizado durante la navegación.
El último añadido fue que recogiese la perfilación del procesador. Esto nos permite hacernos una idea del comportamiento del procesador, las funciones ejecutadas, etcétera, en un determinado sitio web.
Desarrollo del IsKrawler Analyzer
![]()
En este apartado se describen los distintos análisis que se realizan sobre la información obtenida en el crawling. Este analizador nos permite indicarle parámetros a la hora de lanzarlo:
- Verbose (
-v / --verbose) - Eliminar análisis previos (
-rm / --rm-results) - Analizar todos los resultados del crawling (
--all / --analyze-all) - Deshabilitar el uso de VirusTotal (
--dis-vt / --disable-vt) - Exportar los resultados en formato HTML (
--html) - Exportar los resultados en formato HTML en la carpeta de resultados y en /var/www/html (
--htmlvar) - Exportar los resultados a la base de datos (
-db)
Estructura de los resultados:
- results/{url}/{0..9999}/
- /wasm
- /js
El primer módulo analizador que nos encontramos es el analizador de la URL. Dentro de este encontramos los siguientes módulos:
- Ranking top mundial:
- Alexa Static
- SimilarWeb
- Información WHOIS:
- Creation date
- Updated date
- Expiration date
- GeoIP data:
- País
- ASN id- Organization
- Categorización:
- API Symantec
- SimilarWeb
- Webutation
- Mozilla header checker
- TLS checker
- Virus Total
En la fase de crawling se recogen una gran cantidad de ficheros/recursos, por lo tanto, no podía faltar un análisis de estos ficheros, sobretodo de los JS (tanto en línea como en fichero) dado que es código que se ejecuta en el cliente. Tipos de módulos incluidos:
- Ofuscación JSFuck
- JSBeutifier (Desofuscación genérica)
- Buscar orquestadores de Cryptojacking
- JSHint (Syntax)
- Buscar links en los JS
- Buscar funciones eval()
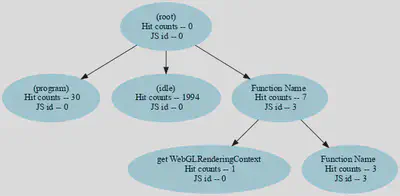
Otro analizador dentro del IsKrawler Analyzer es el del perfilado del procesador. Esto se hace gracias al añadido que se realizó al crawler y esta parte está en gran parte basada en la publicación “How You Get Shot in the Back: A Systematical Study about Cryptojacking in the Real World” de ACM. Esto consiste en:
- Buscar funciones de hash (“Cryptonight”,“sha256”…)
- Tiempo de Hash > normal
- ¿Existe alguna función que sus usos sean muy grandes?
- ¿Es una función periódica?
- ¿Es un tiempo mayor a lo normal?
- Tiempo de la pila > normal
- ¿Existe una cadena de llamadas periódicas?
- ¿Ocupa más del 30% del tiempo de ejecución?
- Creación de un diagrama visual.
Gracias al añadido en el crawler podemos también añadir módulos para analizar la comunicación que se haya realizado mediante WebSockets. Dentro de este analizador se revisan los siguientes puntos:
- Escaneo de la URL con la que se conecta en la API de VirusTotal
- Buscar keywords en los payloads de los frames.
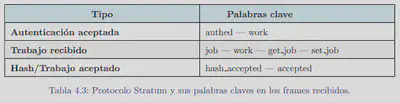
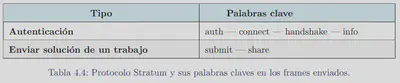
- Creación del diagrama.
El IsKrawler Analyzer también cuenta con un analizador de ficheros WebAssembly, en el que una parte de este análisis se basa en la publicación científica “MineSweeper: An In-depth Look into Drive-by Cryptocurrency Mining and Its Defense”. Puntos importantes de este análisis:
- ¿Existe algún fichero Wasm? (Se revisan los Magic Number)
- Escanear el hash en la API de VirusTotal
- Dos módulos similares para revisar el funcionamiento:
- Haciendo uso del proyecto Octopus.
- Independiente (Basada en la publicación)
Haciendo uso del proyecto Octopus se realiza lo siguiente:
- Desensamblar Wasm to Wabt.
- Crear el Control Flow Graph (CFG)
- Crear el Call Graph
- Function Analytics
En el caso del módulo independiente:
- Desensamblar con WebAssemblyBinaryToolkit (WABT) y la librería subprocess
- Reconocer las funciones mediante expresiones regulares
- Reconocer las llamadas a otras funciones (Call Graph)
- Contar el total de cada operación
- Reconocer bucles y su contenido
- Comparar las caracterizaciones de algoritmos de hash (“Cryptonight”, “Algoritmo genérico”)
El último analizador está compuesto por diversos análisis que debido al tiempo no han conseguido abarcar más. Módulos:
- Módulo para analizar las cookies -> Se hace uso del proyecto Open Cookie Database.
- Módulo para analizar la información de los service workers -> Recoger la cantidad total.
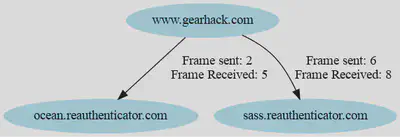
- Módulo para analizar los frames -> Crear un diagrama.
Todos estos análisis nos proporcionan una gran cantidad de información sobre las actividades de la web. Finalmente esta herramienta incluye un “scoring” para determinar si una web es maliciosa, sospechosa o benigna. El “scoring” sería el siguiente:
-
Información del módulo URL:
- !alexa = +1
- !SimilarWeb = +1
- CreationDate - ExpirationDate <= 1 year = +10
- CreationDate <= 1 year = +5
- Webutation < 70 = +10
- Webutation < 50 = +15
- Mozilla Header < 70 = +1
- Mozilla Header < 50 = +5
- Mozilla Header < 25 = +10
- !TLS = +5
-
Información de otros módulos:
- Crypto_orchestrator = +25
- jsfuck = +15
- hash function = +5
- hash > normal = +25
- stack > normal = +10
- ws_crypto = +25
- vt_ws = +25
- vt_wasm = +25
- generic_crypto = +20
- cn_crypto = +25
- ServiceWorkers > 4 = +10
-
Resultados:
- < 35 -> Benigna
- > 35 & < 50 -> Sospechosa
- > 50 -> Maligna
-
Formas para exportar los resultados del IsKrawler Analyzer:
- JSON: Salida estándar que siempre se exporta a la carpeta resultados.
- HTML: Salida más visual y sencilla para el usuario.
- BD: Salida a una base de datos localizada en Heroku.
- Verbose: Salida simple por pantalla.
Ejemplo de la herramienta
En este apartado se muestra un ejemplo del uso de la herramienta. Lanzándola desde consola veríamos lo siguiente al ejecutarlo con los parámetros que deseemos:
El resultado mostrado en la forma HTML sería la siguiente:
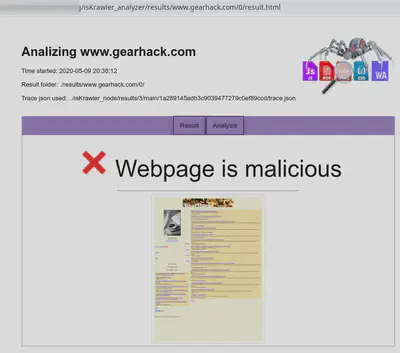
Además del resultado global del análisis, podemos observar también el resultado de los distintos análisis llevados a cabos por cada uno de los módulos:
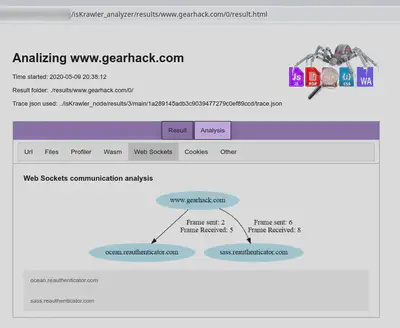
Evaluación de la herramienta in the wild
La herramienta fue probada en grupos de sitios web reales para darle validez y probar su funcionamiento. El primer grupo en el que se probó fue en 400 sitios web de Alexa:
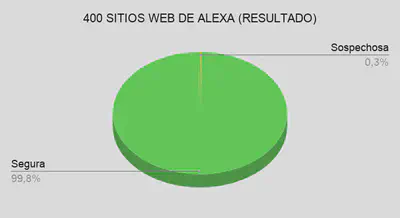
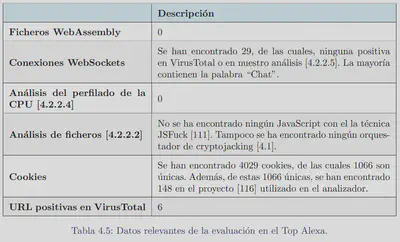
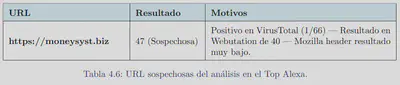
Un segundo grupo en el que se probó la herramienta fue sitios web relacionados con el SARS-CoV-2. Resultados:
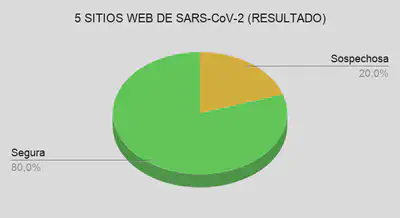
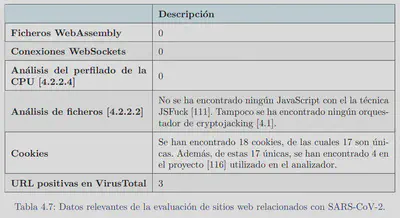
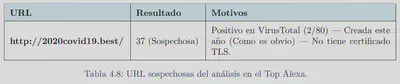
EL tercer grupo que se probó fue en sitios web que en una de las publicaciones indicaban que realizaban Cryptojacking. Hay que tener en cuenta que ha pasado alrededor de un año y medio desde la lista:
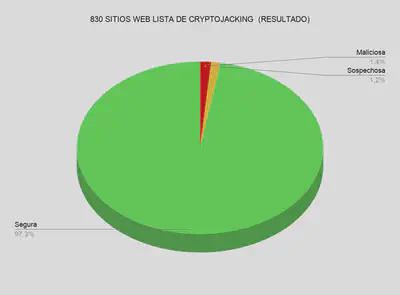


Conclusión
Los siguientes puntos exponen la conclusión de este proyecto:
- Se ha conseguido desarrollar una herramienta ampliable y modular, capaz de evaluar una web de una forma bastante completa.
- La herramienta tiene una gran flexibilidad a la hora de la ejecución y a la hora de exportar los resultados de los análisis, permitiendo elegir al usuario el más conveniente en cada momento.
- Se han integrado publicaciones científicas de gran reconocimiento en la herramienta.
- Se han cumplido con los objetivos preestablecidos al comienzo del proyecto.
Trabajo futuro
A continuación se representan los vectores más importantes del trabajo futuro:
- Mantener la herramienta (Actualizar versiones de librerías…)
- Añadir nuevos módulos de análisis.
- Profundizar y actualizar los ya existentes.
- Dockerizar o virtualizar la herramienta.
- Darle un portal web.
Links
En caso de querer saber más o revisar como planteé tanto la estructura de la memoria como la presentación enlazo lo siguiente:
Alberto Fernandez-de-Retana
Kaixo! My research interests include web security & privacy. In my free time I love to be pizzaiolo.