Has it ever happened to you that your mom searched for something on your computer, such as Christmas decorations or food, and afterwards, you noticed ads for related products appearing on every page you visited?. In this entry, I will explain how web tracking works in the real world, with the goal of providing readers an initial idea of the practice. To achieve this, I will introduce techniques such as device fingerprinting, as well as existing mitigations.
Table of contents
Introduction
What is Web Tracking?
To introduce the topic, I will use an image to explain the idea. Suppose you visit ‘https://foo.com/', which imports an iframe or a simple image from ‘https://tracker.com/'. Later, you visit ‘https://bar.com/', which also imports the same resource. At this point, the third-party agent ‘tracker.com’ has tracked your activity across multiple websites (using cookies). Warning: Third-party cookies have been mitigated in different ways, which we will explore in more detail later.
![]()
How a webpage can identify a User?
In the previous case, the user was tracked using cookies, which is one form of user identification. The cookie was the first mechanism for identifying a user in the stateless HTTP protocol, introduced in 1994 by Netscape (first RFC)(RFC)(Netscape Proposal). Cookies were introduced for cases like online shopping in which the server needs to identify you in order to know your cart of products.
User Identification Mechanisms (aka Device Identification)
The mechanisms to uniquely identify a user are usually split into two main groups:
- Stateful: In these mechanisms the information is stored in the client’s computer. Some examples of this group are: cookies, ETags, localStorage or sessionStorage.
- Stateless: Mechanisms that don’t need to store any kind of information in user devices. These mechanism rely on a set of software/hardware feature that the computer has.
Stateful Techniques
Cookies
The simplest definition of cookies is that they are an identifier generated by the server, which enables the server to recognize the user among other users. The RFC documents linked previously contain the standard formalization of cookies (RFC 1997)(RFC 2011). The term ‘User-Agent’ is used in the RFC to refer to the browser. For further explanation of Cookies.
The nature of cookies is to enable tracking. This tracking could be harmless, such as remembering your session on your bank’s website or saving items in your shopping cart. However, in other cases such as third-party cookies, this tracking extends to following you across different web pages, which compromises the user’s privacy. To use a metaphor, it is not the same for a shop owner to check if you are trying to steal in their shop, as it is to follow you in your daily life.
Cache Metadata: ETags
The ETag (entity tag) header is an HTTP response header that is used to identify a specific version of a resource on the web server. It is typically used for cache validation, allowing web clients to check whether the version of a resource they have in their cache is still current. The main goal of this cache technique is to reduce network traffic and improve the page loading time. In the following draw you can see a simple explanation of how ‘ETag’ header works.

The ETag header is primarily used for caching purposes. However, it could be used for tracking by assigning different ETag keys to each user (demo). In this scenario, when the user visits the website for the second time, the server would receive the ETag containing the user’s ID (link)(year 2000 report)(paper). This idea could also be applied for the tag Last-Modified header (In browsers this data could be required to be a date).
Cache: PNG image
By exploiting the cache, it is possible to track a user’s online activity. For instance, a webpage may embed a PNG image that contains the user’s ID within its content. To retrieve this image/ID for future requests, the webpage specifies that the image should be cached. As a result, subsequent requests made by the user will retrieve the cached version of the image, thus restoring the ID.
HSTS for tracking
HTTP Strict Transport Security (HSTS) is a web security mechanism that allows websites to enforce secure communication (HTTPS) between a client and a server. The mechanism involves implementing a header (strict-transport-security) that instructs the user to establish a secure HTTPS connection instead of an insecure one. This behavior can be leveraged to store a user identifier securely. Frank provides an excellent explanation (blog)(demo webpage) of how to exploit this behavior to generate a user identifier, despite the fact that it was not the intended purpose of HSTS. The following draw provides an illustration of the aforementioned idea:

Cache: Favicon
Favicons images are another technique that can be used to fingerprint a user, taking advantage of the cache. The idea is a little bit similar to HSTS for tracking explained before. In this case I recommend directly the paper (code).
Other script-accessible storage mechanisms
In addition to cookies, modern web browsers offer various other script-accessible storage mechanisms for web applications to store data on the client-side. These storage options provide web developers with more flexibility in managing user data and preferences, and can help improve web performance and user experience. Some of the most commonly used storage mechanisms include localStorage, sessionStorage, JavaScript Objects (e.g., window.name or navigator), IndexedDB and WebSQL.
Putting the Puzzle Together: Evercookie project
Evercookie (code) (webpage) is a project that utilizes a variety of techniques to persistently store user identifiers, and will attempt to recreate them if they are deleted from any of the storage methods. These techniques are: Standard Cookies, Flash Local Shared Objects (Deprecated), Silverlight Isolated Storage (Deprecated), CSS History Knocking (Deprecated), ETags, Web Cache, HSTS, window.name, userData Storage (Deprecated), sessionStorage, localStorage, Web SQL, PNG image, IndexedDB and Java Applet techniques (Deprecated).
Stateless Techniques (aka Device fingerprinting)
Device fingerprinting refers to the ability to identify a device based on its unique software or hardware characteristics. The objective of these methods is to obtain as many features as possible in order to generate a more unique identifier. In the following table, I expose some stateless methods:
| Mechanism | Origin | Type |
|---|---|---|
| User-Agent | HTTP Header | Attribute-based |
| Accept-Language | HTTP Header | Attribute-based |
| screen resolution | JavaScript API | Hardware-based |
| Canvas, WebGL | JavaScript API | Hardware-based |
| Mobile Sensors | JavaScript API | Hardware-based |
| … | … | … |
If you want to check the code snippet for some of these methods, you can check out the well-known library ‘fingerprintjs’.
XS Leaks for Web Tracking
XS Leaks can also be used to fingerprint a user. For instance, suppose the user has previously visited “https://foo.com/". In this case, there are two straightforward examples. First example: if a new webpage contains a link to “https://foo.com/", the link will appear in a different color because the user has already visited it (blog). Second example: if the new webpage imports an iframe of the “https://foo.com/" webpage and then loads an image that can be displayed in the iframe, the image’s loading time will vary depending on whether it has successfully loaded inside the iframe. This difference in loading time can be used to fingerprint the user. This second example was patched some years ago addind the key of the top-level frame for the cache key. Another simple example of XSLeaks for fingerprinting is the Performance API. This API implementation allowed for very precise measurement of how long a computer takes to complete an operation, which could be used to differentiate between devices and fingerprint them. However, this technique was patched by reducing the precision of the API. I suggest referring to the web for further information on this topic (XS Leaks Website).
Other stateless methods
Other examples of stateless methods that are less commonly found in the wild have been discovered. One of them is a study of fingerprinting a user by their typing cadence, which checks the speed of a person typing their credentials in order to create a pattern (link). Another example of such a method is scanning localhost ports using websockets in order to check services listening in any port (e.g., Discord). If you want to understand more this last technique I recommend a previous article in this web (link). Similar to the websockets technique, in which the webpage could check some common desktop applications, there is another technique called ‘scheme flooding’ that checks custom protocol (e.g., msteams://, skype://, spotify://…). The article for this technique is published in the following page (link).
Web Tracking in-the-Wild
As the reader may notice, cookies can be used to track a user across different websites (research paper). The first web tracker was cookie-based and was discovered in 1996 in microsoft.com from digital.net. This tracker was found by an ‘archaeological’ study conducted by Lerner et al. (link), who used the Wayback Machine (Archive project). For this term, I recommend the following research article by Franziska Roesner as a suggested reading (link) which introduces the topic very well. Let’s take one of the previous examples to illustrate the most basic tracking behavior:
![]()
In the figure, the third-party agent (bar.com) will know the different webpages Groot and Baby Yoda have visited by embedding an image. This technique also applies to other tags such as <iframe>.
document.referer
The “document referer” is an HTTP header that indicates the webpage from which the user came from. As shown in the following illustration, this header can be problematic when it discloses not only the domain from which the user came from, but also the entire URL including its parameters (e.g., cookie as param or a path that you need to be logged). Similar to the previous one, browsers implement constrains for this header.

Bounce Tracking (coming soon…)
Trackers’ Gossip: Sharing Information
In order to construct a more comprehensive user profile, third-party domains must combine the profiles they have gathered from various websites. Cookie syncing is one of the most well-known methods for accomplishing this. I highly recommend the paper of Nataliia Bielova in this topic (link). In the following picture from Nataliia’s paper you can see a basic example of one domain (A.com) sharing his cookie with another domain, so in that case the second domain (B.com) will know that for the site A.com the user has the cookie id=1234.
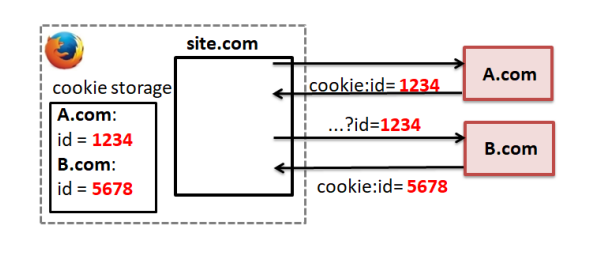
In the following subsections I will talk about some of these techniques.
Invisible Pixels
Invisible pixels are empty elements used for tracking or for sharing information among trackers. One example would be an empty image or an image of 1x1 size.
![]()
Identifier as a URL parameter
A technique that has been observed to circumvent mitigations meant to block third-party cookies (explained later) involves adding the cookie or a identifier as a parameter within the URL. It’s worth noting that this technique isn’t solely utilized for tracking purposes, as it can also be used for login functionalities. To provide a clearer understanding of this technique, here’s a simplified representation of the Google login process as an example.

It’s important to note that this technique has also been addressed by certain browser mitigations, such as parameter blacklisting, which we’ll discuss in more detail shortly.
Identifying Information
In this entry, I’ve covered numerous techniques that don’t require any personal information from the user. However, what if you are logged with your email address?”

This technique takes advantage of your ‘stable’ information like the email address. Asuman Senol et. al. (conference) presented a study demonstrating that form information (e.g., email adress) can be sent without clicking the submission button.
Mitigations
Compatibility with the web ecosystem is often a significant concern in the deployment of mitigations for web security and privacy issues. In other words, it could happen that the deployment of a mitigation can break your bank login. In such a scenario, the user may adopt one of two approaches. The first option is to attempt logging into their bank account using a different browser vendor. The second option is to disable any mitigation measures implemented by the browser. This is one of mainly issues when a mitigation is applied in the web ecosystem.
Generic solutions
There is no universal solution for all types of web tracking. The DoNotTrack header was introduced in 2009 as a means for users to indicate their preference for being tracked. However, this header has since been deprecated and, in some cases, has been repurposed as an additional feature for device identification.
Disabling JavaScript by default is another potential solution to limit web tracking, although it may render your daily internet use impossible. If you also disable cookies and cache, it could significantly reduce your chances of being tracked. To reduce the entropy of device fingerprinting and the fingerprinting surface, vendors have attempted to standardize most of the browser features. This means that if two devices return the same values, it would be difficult to determine which of them visited a webpage. For instance, features like the User-Agent header, browser languages, fonts, etc. are commonly standardized. The World Wide Web Consortium (w3c) provides an article for general mitigation of browser fingerprinting in Web Specifications (link). Although not a foolproof approach (paper, paper2, paper3…), one potential remedy is to utilize blacklisting or heuristics to identify tracking components within the webpage. This technique is very common among extensions, such as ad and tracking blocking extensions.
Specific defenses
Storage mitigation
A solution to cookie tracking that is being applied in some browsers is the limitation/blocking of third-party storage (e.g., Cookies, localStorage…). This mitigation applies not only cookies but also DOM Storage (localStorage, sessionStorage and IndexedDB), Cache (HTTP, image, favicon, HSTS…), Broadcast Channel and Shared Workers. In the following image the reader can see the two different mitigation in this kind. The example shows cookies for simplifying the draw.

State 0 means when the browser/User-Agent has no protection for storage. In that case, the User Identifier (UID) saved by the 3-party will remain for each of the visited page (if included) and would allow to track the user. The purpose of deploying Mitigation 1 as an interim measure was to prevent all web pages that use any type of storage methods (cookie, localStorage…) from being disrupted. In the case of Brave, this solution was called Ephemeral Storage. In the case of Firefox is called State Partitioning. In simple words, the solution is basically to add the Top-Level-Frame as a key in the moment of the storage, so if this third party is embedded in another (top-level-frame) webpage it would have an empty storage and if returns to the key (top-level-frame, iframe) it would have the previous storage. The final perfect mitigation is basically blocking any type of storage mechanisms of 3-party.
To gain insight into the mitigation and minor performance decrease of HTTP Cache, I suggest referring to this concise article (link). There are still some cases which are not partitioned (link/Brave Article) and also there are some methods to ‘bypass’ or get access to the 1-party context(Storage Access API). (SPAM ON 🪺) For this problem, I wrote the following article: Storage Partitioning (SPAM OFF 🪺).
HSTS mitigation
In certain browsers, the previous mitigation explained would impact the HSTS cache. Since the previous solution was not completely effective in mitigating this attack, so different solutions have applied. In the case of webkit they implement some techniques to limit this attack, such as, limiting HSTS State to the Hostname or eTLD+1. For Brave, they applied a solution in which the HSTS Cache is removed after the webpage is closed link.
Referer mitigation
The referer-policy HTTP response header is used to control how much information is included in the Referer header when a user clicks on a link or visits a page. In order to mitigate the referer, one can reduce the header to only include the domain, particularly when it is a cross-origin request (removing path and parameters).
Brave Mitigation (code/code2): They use strict-origin-when-cross-origin value of the referrer policy as default.
Webkit: referrer header “is downgraded to just the page’s origin for third party requests to domains that have been classified as possible trackers by ITP and have not received user interaction.”.
Bounce Tracking mitigation (coming soon…)
Query Parameters mitigation
As previously stated, using URL request parameters is one way to exchange information between pages. To address this issue, an extended approach is to create a blacklist of commonly used tracking parameters in the URL. Some of these parameters are included in the webpage PrivacyTests. In the following snippet code of brave browser (Github), some tracking parameters that are removed are shown:
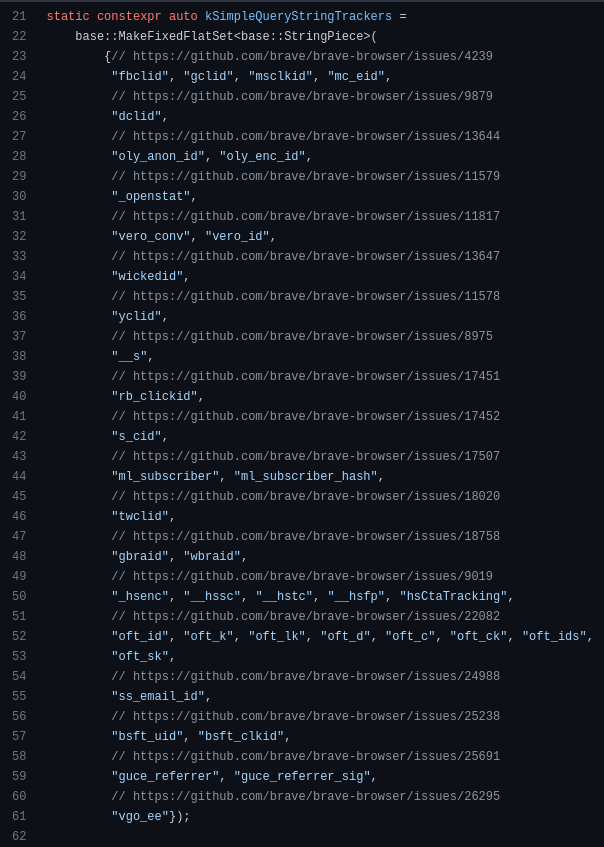
An important challenge in addressing this privacy concern is the difficulty in determining whether a parameter is serving as an identifier, a timestamp, or another undefined goal. Audrey et. al. [paper] presented a contribution trying to identify this User Identifiers (UID) in parameters.
Hardware-based attributes mitigation
In the context of hardware-based fingerprinting, one proposed solution is randomization. Essentially, this involves WebAPIs (such as canvas) that are typically used for fingerprinting returning a random value each time a page is visited, or when a user closes and reopens the browser. The Brave Browser also adopts a similar strategy known as “farbling”, where the API’s typical output is deliberately randomized with insignificant variations that would go unnoticed by human users. These “farbled” values are deterministically generated using a per-session, per-eTLD+1 seed2 so that a site will get the exact same value each time it tries to fingerprint within the same session, but that different sites will get different values, and the same site will get different values on the next session (blog). In some cases this techniques are really difficult to deploy (issue).
In other fingerprinting techniques, such as performance fingerprinting, a mitigation that has been implemented involves reducing the precision of the WebAPIs within the Performance category. For example, instead of returning values in microseconds, the precision has been reduced to milliseconds.
Conclusion
In this article, I have primarily focused on desktop fingerprinting, but web tracking on Android devices could potentially be more severe. Mitigating web tracking can be challenging, as some of these techniques are integral to the functioning of the web ecosystem, and they are also utilized to differentiate between human users and bots. There is a substantial amount of academic research in this area, and I highly recommend keeping up-to-date with new publications. As the web ecosystem continues to evolve and introduce new features like a new WebAPI, it may uncover novel “opportunities” for new security and privacy concerns. If you want to check a survey in this topic I recommend Laperdrix’s paper.
When playing hide and seek, it’s often better to hide where everyone else is hiding rather than going it alone. If you get caught in the first case, there’s still a chance that you might make it out safely. But if you’re hiding by yourself and get found, that’s game over.
Browsers Privacy Comparison
Arthur Edelstein has undertaken a project to compare the various mechanisms offered by the leading web browsers. If you’re interested in exploring the differences, I highly recommend visiting his project PrivacyTest. For a more comprehensive analysis of each browser’s defenses, I suggest checking out their developers’ blogs (webkit/brave) or, in some instances, delving directly into the code (chromium/brave). Some of these implementations could lead to unexpected leaks, such as Intelligent Tracking Prevention (ITP) non-default feature of Safari (Information Leaks via Safari’s Intelligent Tracking Prevention).
Historical Notes
In this section, I would like to bring attention to significant points from the Cookie RFCs. One notable aspect of the RFC from 1997 is that it includes a section that discusses the potential privacy concerns associated with cookie sharing.
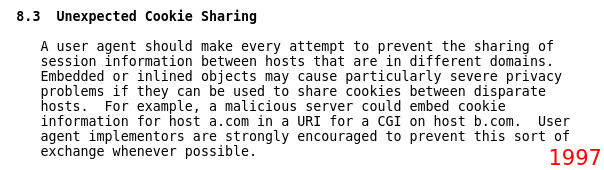
The standard RFC for cookies further elaborates on these concerns. In this latest RFC, they explicitly discuss web tracking and third-party tracking. In the final sentence, they also mention that trackers could potentially bypass cookie-blocking measures by using parameters within the URL.

Thanks for reading
If you have any recommendation/mistake/feedback, feel free to reach me twitter :)
References:
- Recommended: Fingeprinting Article Chromium (Artur Janc and Michal Zalewski)
- Recommended: Fingeprinting Article WebKit
- Panopticlick/CoverYourTracks: Link
- Fingerprintjs2. Get your FP: Link.